Streaming RSS Feeds with PyArrow Acero, Delta Lake and OpenAI
Project Overview
The acero-delta-lake-streaming proof of concept demonstrates how to listen to an RSS feed and stream all the changes into a Data Lake to run data analytics. As part of the pipeline, it identifies and extracts the identity of the actors and their roles from the news articles. Data transformation are done with Acero, the experimental streaming engine from Apache Arrow, with Delta Lake, a format open-sourced by Databricks to structure data lakes as tables.
What is Apache Arrow?
Apache Arrow is a language-agnostic format that organizes data in memory for fast columnar computations. Unlike previous memory representation, it groups the data of different rows by column, allowing iterating and aggregating columns faster. Besides representing the data, it also brings a set of libraries to store, extract, and transform the data in different programming languages (Python, Rust, C++, Go,...). The efficiency and interoperability make it ideal to exchange in-memory data between storage, compute, and analytics software. In this proof of concept, we use PyArrow to access Apache Arrow from Python, with most computations handled in C++ for efficiency.
Loading...
What is Acero?
Acero is an experimental streaming execution engine developed as part of the PyArrow project. It is designed for low-latency, high-throughput streaming workloads, making it ideal for real-time data processing tasks.
Unlike traditional engines, Acero is not a distributed engine, meaning it does not run across a cluster of machines by default. Instead, Acero focuses on single-node streaming execution, with the ability to scale out by leveraging orchestration frameworks or external systems (e.g. Dagster, Apache Airflow).
Loading...
What is Delta Lake?
Delta Lake is a storage format to organize information as tables into a data lake, bringing many of the properties of databases such as ACID transactions, schema evolution, and time travel while being reliable, efficient, and cost-effective.
Developed and open-sourced by Databricks, it is compatible with most cloud object storages (e.g. AWS S3, GCP Cloud Storage, Azure Blob Storage) but also can be run on-prem. The deployment method might vary, and sometimes an external database is used to ensure that transaction comply with ACID.
Originally developed to store and read data from Apache Spark, nowadays there are many connectors that enable writing and reading Delta Lake tables from many programming languages and tools. In this proof of concept we use delta-rs, it brings a Python interface to read and write a Delta Lake table, delegating the expensive computation to the Rust core.
Breaking Down the Code
The steps performed are as follows; first, we call create_press_releases_sources which pulls the data of all the RSS Feeds and defines an Arrow table.
Then, we iterate over the list of sources (Arrow tables) and apply the project in the curate_news, at this point , Acero will start to iterate over the batches of records from in-memory Arrow table. In our project we only rearrange the oder of columns, but one could delete or add a new column, and transform the elements of a column with PyArrow Compute Functions.
Finally, by calling store, as you could expect, we append the new data into the Delta Table.
Loading...
Downloading RSS Feed data
We define a schema for our Delta table that will store the RSS feed data. The schema includes fields for the title, publication time, link, description, thumbnail URL, and category.
Loading...
Analyze the Data
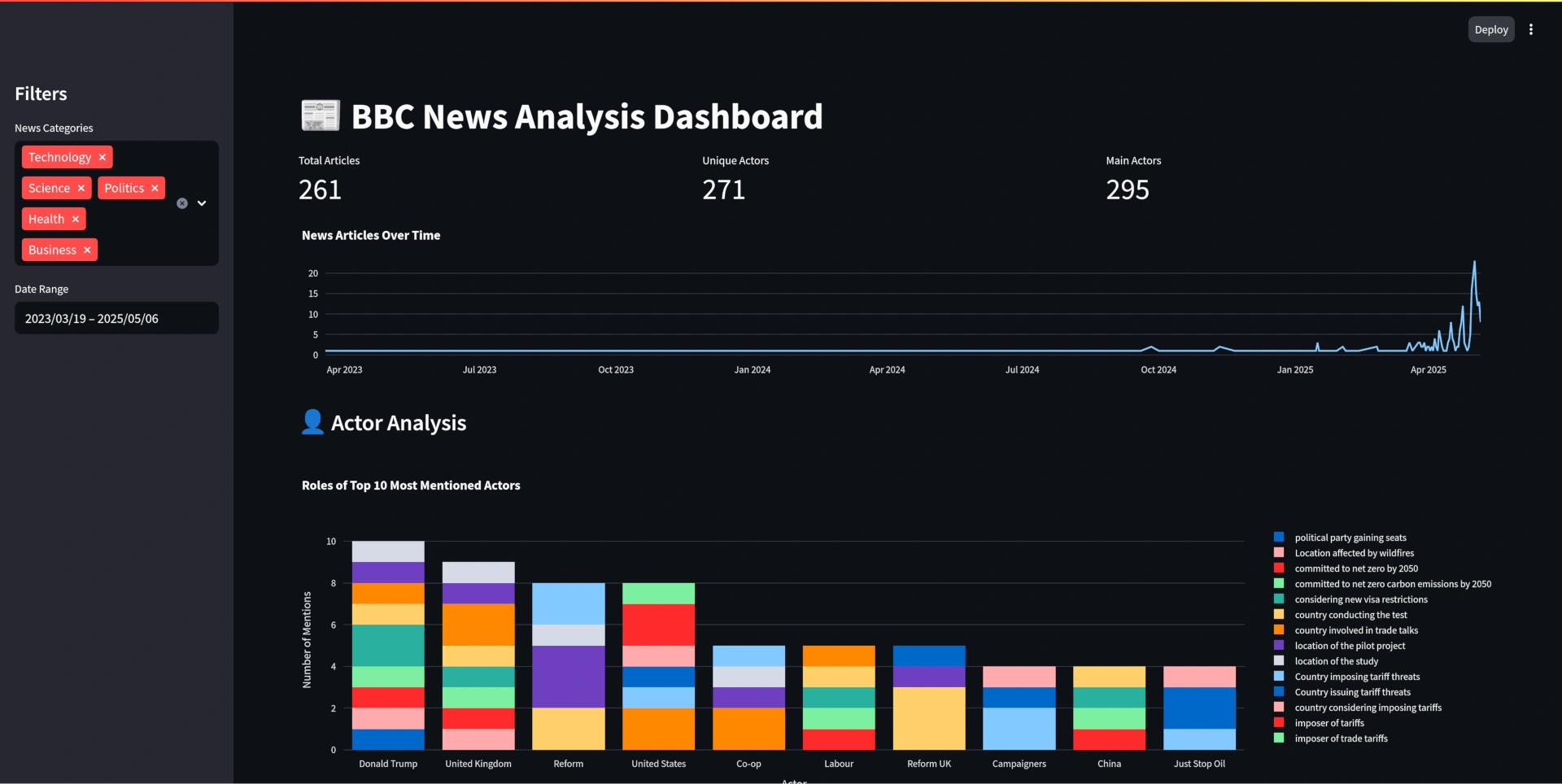
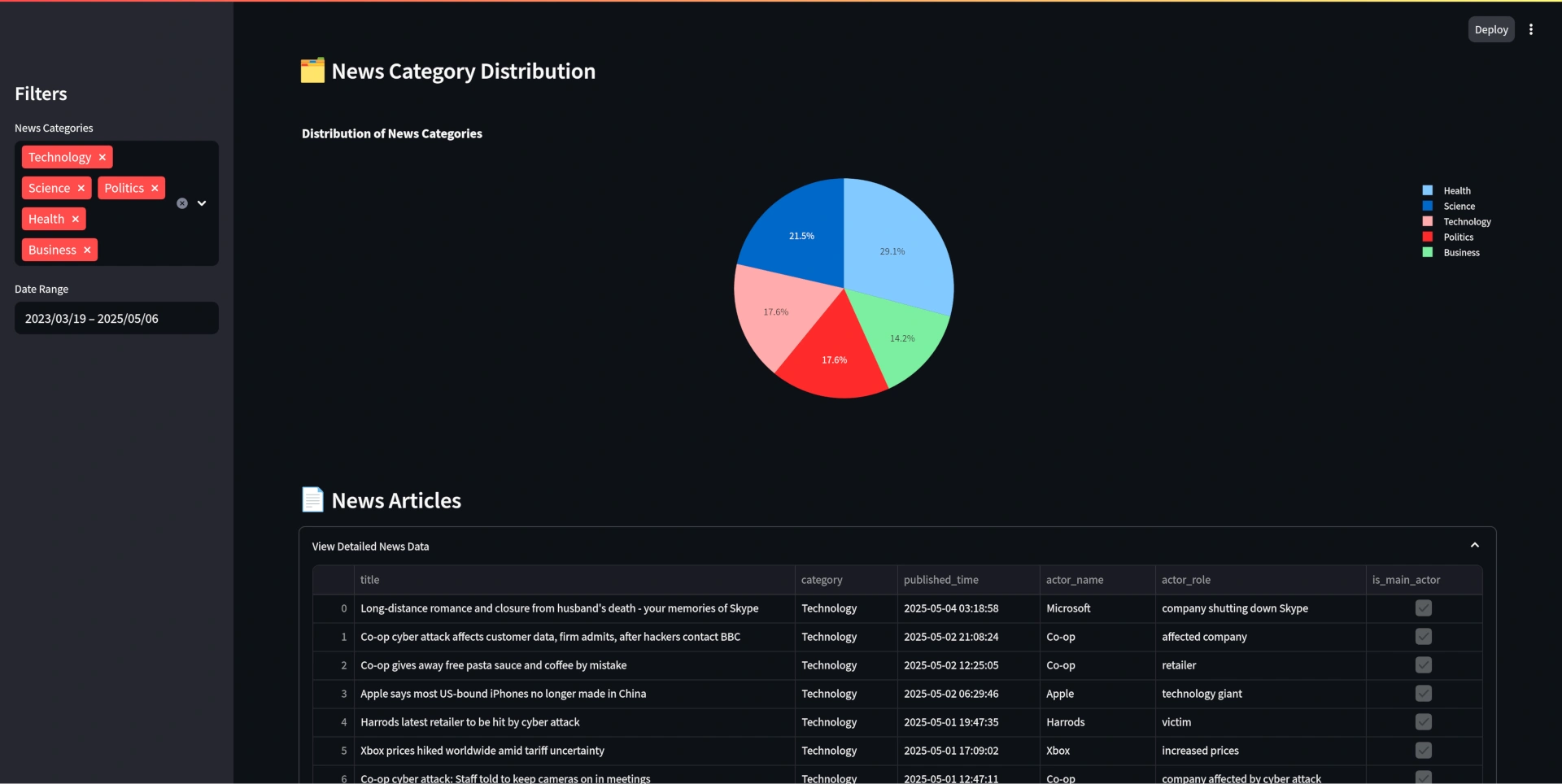
You can easily visualize the data with a dashboard, in my case I created a simple dashboard with Streamlit. It includes a timeline of the news, information about the entities detected and their roles in the news, a distribution of the categories, and a detailed view of a news article. It can be launched easily with:
Loading...
If you want to perform some data analytics, you can easily access the data from the Delta Lake table with:
Loading...
And analyze or transform with your preferred library:
Loading...
If you want to analyze the actors and their roles, you can do it with:
Loading...
Improvements Needed
- Store the RSS item IDs in a database with quick lookups.
- Enrich the data by extracting the named entities with an LLM or a NER library.
- Fail-over mechanisms to restart a failed pipeline and keep consistency.
- Strategy to paralellize pipelines and keep them running 24/7.
- The model produces a high cardinality of roles.
- Acero is a streaming engine but requires an orchestrator to keep the tasks running in a loop, and to monitor them (e.g. Dagster, Prefect, Airflow, ...).
- The extraction of entities should be optimized by introducing concurrency. They are extracted sequentially, and data is transformed several times.